
开始
C语言课程视频作业要求每人每周录制七个解题视频任务,两个专业一共有一百五十多人加二十多位助教。显然,这项作业将产生大量的视频文件,平均每周会产出近千个视频,因此我在百度云上建立了两个共享文件夹,并写了个简单的脚本为两个专业的每个学生建立了视频存储的结构:
def gen_stu_struct():
import os
if not os.path.exists(path + '2020') or not os.path.isdir(path + '2020'):
os.mkdir(path + '2020')
os.mkdir(path + '2020/电子信息工程')
os.mkdir(path + '2020/计算机科学与技术')
for i in group:
if not os.path.exists(path + '2020/电子信息工程/' + i):
os.mkdir(path + '2020/电子信息工程/' + i)
os.mkdir(path + '2020/计算机科学与技术/' + i)
for mem in group[i]:
prof = profession[mem]
os.mkdir(path + '2020/' + prof + '/' + i + '/' + mem)
os.system('echo "ignore" > ' + path + '2020/' + prof + '/' + i + '/' + mem +
'/.ignore')
简单看就是,专业->助教->学生的结构,然后学生把视频作业上传到自己所属的文件夹中,此时,统计视频提交情况是比较困难的~
获取视频作业目录结构
不得不说,油猴是个强大的浏览器扩展,多亏了它,俺四处寻觅了一下,就找到了合适的爬虫脚本:

点击导出目录信息后,等待一段时间会得到一个html文件,里面有一段js塞满了目录的数据,将它提取出来写成json文件,就得到了下面的东西:(按照文件树DFS序生成的列表)
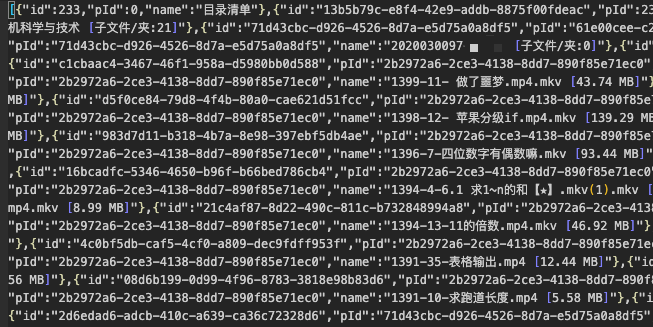
接下来我们本地处理这个数据即可~
处理数据
程序扫描
-
学生的视频录制任务是存在本地的,任务可以被
竞赛号 + 题号进行唯一标记,因此,只需要在遍历列表时匹配文件名的前两个数字,再进行一些简单的文本处理就可以识别到学生提交的视频任务。res = [int(i) for i in re.findall('\d+', name)] res[1] = res[1] if res[1] < 100 else res[1] % 100 if rt_dir in stuStatus and rt_dir not in current_status: current_status[rt_dir] = set() current_status[rt_dir].add('%d题目集 %d题目' % (res[0], res[1])) -
接下来,对比学生
实际提交任务的列表与规定的任务列表就可以判断学生是否足额提交作业。for i in stuStatus: if i in current_status: ls = [] for j in current_status[i]: if j in stuStatus[i]: stuStatus[i].remove(j) ls.append(j) for j in ls: current_status[i].remove(j) for i in stuStatus: if stuStatus[i]: ls, has_use = [], set() for prob in stuStatus[i]: if prob == 'lucky guy': ls.append((prob, '')) continue rest_problem = int(re.findall('\d+', prob)[0]) if (rest_problem not in rp_ls) or ( i not in current_status): # 题目不可替换 或 没有提交任何题目 continue for replacable in current_status[i]: if replacable in has_use: continue rid = int(re.findall('\d+', replacable)[0]) if rid in rp_ls: ls.append((prob, replacable)) has_use.add(replacable) break for item in ls: stuStatus[i].remove(item[0]) if item[1]: current_status[i].remove(item[1]) -
最后,将对比结果输出为一个文本文件,针对存在问题的学生进行人工甄别。
for i in list(stuStatus.keys()): if i not in stuTA: continue if not stuStatus[i]: stuStatus.pop(i) else: print('%s: %s vs %s => %s' % (i, stuStatus[i], current_status[i] if i in current_status and current_status[i] else '{}', stuTA[i] if i in stuTA else 'None'))
人工甄别
经历程序扫描后被保留下来的存在问题的学生,主要有以下几种可能的问题:
- 未提交: 确实没有提交作业
- 任务缺失: 缺失部分作业
- 任务错误: 提交的任务和被分配的任务不一致
- 命名错误: 命名不规范或错误命名导致的错误(视改正难度帮助修改)

评论